AEON devlog — a trainability bug in the liquid-neural-network brain
This is a development log, not a result. AEON is an experimental prototype and it stays one; the point of writing this down is that the process of finding and fixing a bug is often more honest — and more useful — than any headline. The full system overview lives in AEON’s technical whitepaper; this post is about a single thread I pulled on this week.
what shipped, and where it broke
AEON’s latest update (the project page has the overview, the code is on GitHub) added spatial embodiment for citizens — real positions, pathfinding, movement intents — along with a teacher→student learning curriculum and a sized student network you can scale and swap live. The student is a CfC (Closed-form Continuous-time) liquid neural network: a continuous-time recurrent net that treats a citizen’s life as an irregular time series.
Before any of that goes out, it runs through the validation sweep. And the sweep caught something:
FAILED tests/test_trainer_overfits_a_batch — assert 0.671875 > 0.7That test is a deliberately blunt sanity check: take 64 examples with a perfectly separable feature→action mapping (four classes, one constant feature each), train on them, and confirm the network can memorize the batch. If a learning system can’t overfit a trivial fixed set, something is wrong with the optimization — not the data. The student got 67.2% where the test wanted 70%, and the failure reproduced deterministically.
why a marginal miss was worth stopping for
It would have been easy to read “0.672 vs 0.70” as a too-strict threshold and move the bar. That’s exactly the move worth resisting. The honest question isn’t “how do I make the test pass” — it’s “why can’t a network with plenty of capacity memorize four classes?” A learning system that can’t reliably learn a trivial mapping is a real problem, whatever the threshold says.
So instead of touching the assertion, I went looking for the cause.
the investigation
First I ruled out the obvious suspects in the new code. The update had added a multi-task target head and a disagreement-replay mechanism that appends hard examples back into the training set. The replay turned out to grow the “fixed” batch from 64 to ~180 samples mid-run — real pollution of the overfit test — but disabling it didn’t fix the problem. Neither did giving the optimizer 3× more steps, nor a higher learning rate.
What did surface the truth was sweeping the random seed. The same training run, same data, only the initialization changed:
| random seed | 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| action accuracy | 0.78 | 0.44 | 1.00 | 0.25 | 0.42 | 0.47 |
Seed 2 nailed it. Seed 3 sat at 0.25 — pure chance for four classes. The network wasn’t underfitting; for some initializations it was collapsing to a single class and never recovering, even with more steps. The original test had only ever run on one seed and happened to land on a lucky one; the new code nudged that seed just under the bar. The marginal failure was a symptom of a much wider instability.
root cause: an unnormalized recurrence
The CfC cell fed its own hidden state back into a linear layer with no normalization anywhere in the loop:
# before
z = torch.tanh(self.backbone(torch.cat([x, h], dim=-1)))That is a classic recipe for seed-dependent recurrent dynamics. For some initializations the fed-back state drives the pre-activation into a regime where the input differences between classes wash out, and the downstream heads have nothing left to separate. It trains fine when the initial weights happen to keep the dynamics in a good range, and falls apart when they don’t — which is exactly the all-or-nothing pattern the seed sweep showed.
the fix: one LayerNorm
The standard remedy for unstable recurrent trainability is to normalize the recurrent pre-activation. One line:
# after
self.ln = nn.LayerNorm(hidden) # in __init__
z = torch.tanh(self.ln(self.backbone(torch.cat([x, h], dim=-1))))The effect across the same six seeds:
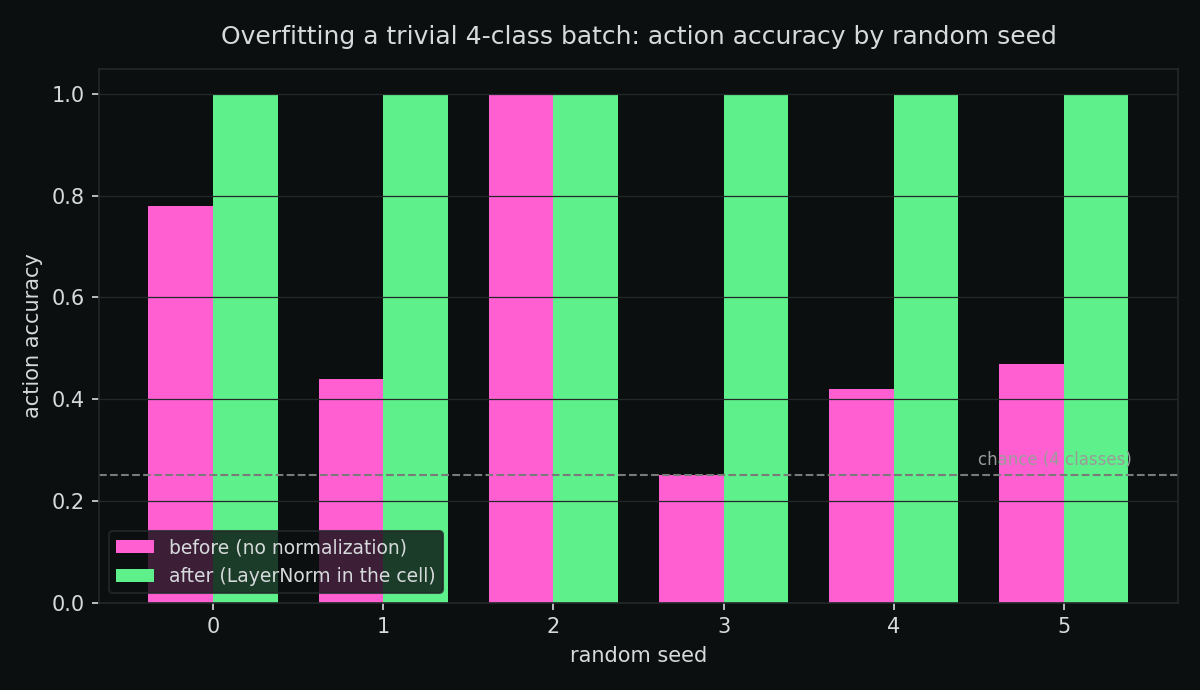
Every seed converges to 100%. The chaotic, init-dependent behavior is gone.
why this is a real fix, not a test hack
This is the distinction I care about most. There are two ways to make a red test green: weaken the test, or fix the thing it’s testing.
- The assertion was not changed — it still demands the student actually learn.
- The fix is in the production network, not the test harness: it’s a property of the model every citizen’s brain now inherits, not a special case for one unit test.
- It removed an instability that existed independent of the test — the seed sweep proves the network was failing to train on a third of initializations regardless of any assertion.
Normalization doesn’t make the network “smarter” in any measured sense, and I’m not claiming it does — AEON’s emergent behavior is still unmeasured and framed as engineering, not a result. What it does is make the student trainable reliably instead of by luck. That’s a smaller, more honest claim, and it’s the one the evidence supports.
validation
The fix went through the same gate that caught the bug:
- The targeted mind/trainer/model-size tests: 33 passed, including the formerly-failing overfit test and the parameter-count checks (the LayerNorm’s added parameters are negligible).
- The full suite — byte-compile, the complete pytest run (~22 minutes), and a JS syntax pass: 193 passed, zero failures.
Then it shipped to main.
what comes next
This was one thread. The whitepaper’s roadmap lists the bigger ones honestly: long-run soak testing (determinism and drift across tens of thousands of ticks), dirty-propagation and payload budgets for the renderer, and turning historical sites into a first-class feedback field the simulation can actually feel. AEON is built in public on GitHub, and it sits inside a wider local-first research program — the same evidence-first approach behind the memory benchmarks applies here, even when the artifact is a devlog rather than a proof drop.
The lesson I’m keeping: when a learning system fails a trivial test, believe the test before you believe the threshold. The bug is usually realer than it looks.
Yan Desbiens — work conducted at Éthiqueia Québec inc. A development log from AEON: Living Worlds.