proof drop Memory Systems
proof drop #1 — running a 24 GB model on a 24 GB GPU (and the honest catch)
This is the first formal proof drop for the lab. The rule for these is simple: every claim is reproducible from a one-command script, or it’s marked speculative. No exceptions, no hype.
The claim under test:
Can UFM run a routed model whose expert bank is larger than VRAM, on a single RTX 4090 — and what does it cost?
the setup
A token-choice Mixture-of-Experts. The experts dominate memory, but only a few fire per token — that sparsity is the whole opportunity. I sweep the number of experts upward and place them three ways:
- baseline — all experts resident on the GPU. Fastest, until it runs out of memory.
- naive offload — experts live on CPU, copied to the GPU and back on every call. Fits in almost no VRAM, but pays the transfer every step.
- UFM — experts live on CPU (pinned); UFM pages them in on demand and keeps the hot ones resident (LRU). Fits, and caches.
Each expert is a 33.6M-param MLP (d_model=2048, d_hidden=8192) — 0.125 GB in fp32.
At 192 experts the bank is 24.0 GB, just past the 4090’s 23.5 GB.
the result
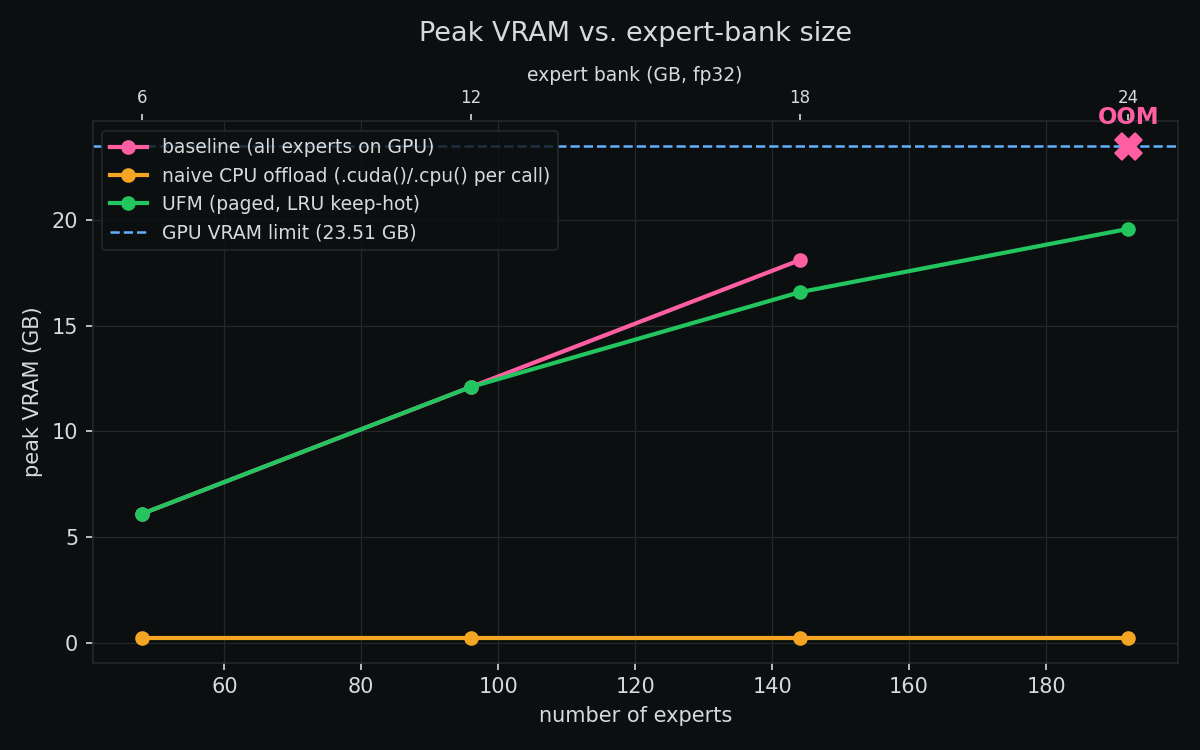
At 192 experts, baseline OOMs — the 24 GB bank doesn’t fit. UFM runs the same model, holding VRAM at 19.6 GB. Naive offload also fits, flat at ~0.2 GB. So far, both alternatives “work.”
The interesting part is throughput:
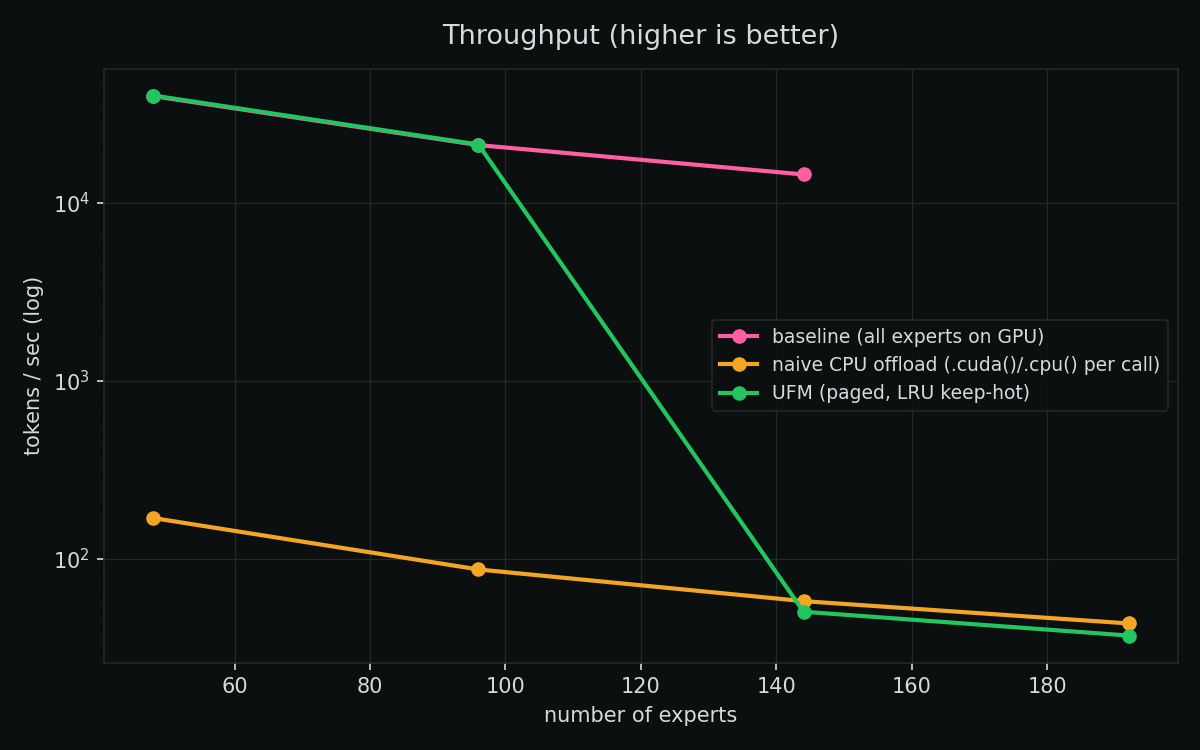
| experts | bank | baseline | naive offload | UFM |
|---|---|---|---|---|
| 96 | 12 GB | 21,017 tok/s | 87 tok/s | 21,174 tok/s |
| 144 | 18 GB | 14,374 tok/s | 58 tok/s | 50 tok/s |
| 192 | 24 GB | OOM | 43 tok/s | 37 tok/s |
Two things jump out.
When the working set fits the budget, paging is nearly free. At 96 experts (12 GB ≤ UFM’s 16 GB target), UFM runs at 21,174 tok/s — within ~1% of baseline, and ~240× faster than naive offload. The experts get paged in once and reused; the cache does its job.
And the honest catch. At 192 experts this synthetic workload routes 512 tokens across almost all 192 experts — so nearly every expert fires every step. The working set (24 GB) is far bigger than the budget (16 GB), nothing gets reused, and UFM (37 tok/s) lands on par with — even slightly behind — naive streaming (43). When you genuinely touch everything every step, you’re transfer-bound, and a cache can’t save you.
what this actually means
UFM is not magic memory. It’s a bet on locality. If your routing has any — if the active working set fits the VRAM budget — UFM gives you full-GPU throughput on a model that shouldn’t fit. If your routing touches everything every step, you’re bandwidth-bound and you need more memory or better routing, not a pager.
That’s a useful, honest tool: “run models larger than your VRAM, at full speed, as long as you’re not touching all of it at once.” For a lot of real MoE inference, that’s exactly the situation.
reproduce it
git clone https://github.com/Linutesto/ufm && cd ufm
pip install -e . && pip install psutil matplotlib
cd benchmarks && ./run.shThe script prints your exact GPU/driver/torch versions, captures OOMs as results instead of
hiding them, and writes every number to results/. Hardware here: RTX 4090 (23.5 GB),
driver 580.126.18, torch 2.10.0+cu128. Full method, caveats, and the training-vs-inference
limitations are in the benchmark README.
limitations (so you don’t over-read this)
- This is inference (
torch.no_grad). UFM v0.1 paging is forward-safe; training-time autograd across evicted params is future work. - fp32 experts (bf16 ≈ doubles what fits). Small-batch throughput. Single machine, single run — indicative, not a leaderboard.
- Eviction is plain LRU; cost-aware eviction and an NVMe tier are on the roadmap.
This is the lab’s thesis in one experiment: capable AI you can own, on commodity hardware, through memory that organizes itself. One 4090, a model that doesn’t fit, and an honest account of when the trick works and when it doesn’t.
Yan Desbiens — work conducted at Éthiqueia Québec inc. Proof drop #1 of an ongoing series.