proof drop Commodity Training
What it costs to train an LLM from scratch on one RTX 4090
This is a proof drop. Rule: every claim is reproducible from a one-command script, or it’s marked speculative. This one is all engineering numbers — measured on the card on my desk.
the claim
A single consumer RTX 4090 (24 GB) pretrains the entire 30M–500M model family from scratch, and the practical cost is better than the conservative spec sheet — not worse.
the setup
ForgeLM is my from-scratch training stack: Llama-style
decoder (RMSNorm, SwiGLU, RoPE, GQA), bf16, FlashAttention via
F.scaled_dot_product_attention, torch.compile. One RTX 4090 (Ada, sm_89), 24 GB. Nothing
in the cloud.
Two kinds of number here, kept deliberately separate:
forge planruns real forward + backward + optimizer steps and reports steady-state VRAM and throughput.torch.compileis off for the planner, so it’s a conservative floor. Reproducible in a minute per config.- The loss curve is from an actual 120M pretraining run (
torch.compileon).
the result
the training envelope (measured 2026-06-29)
| Config | Params | Micro-batch × seq | Train VRAM | Throughput | Tokens/day |
|---|---|---|---|---|---|
| 30M | 31,793,664 | 24 × 1024 | 10.1 GB | 251,153 tok/s | 21.7 B |
| 60M | 55,719,040 | 12 × 2048 | 13.1 GB | 146,599 tok/s | 12.7 B |
| 120M | 112,678,656 | 8 × 2048 | 15.8 GB | 84,554 tok/s | 7.3 B |
| 250M | 254,321,664 | 4 × 2048 | 13.2 GB | 44,587 tok/s | 3.9 B |
| 500M | 570,658,176 | 4 × 2048 | 20.4 GB | 22,279 tok/s | 1.9 B |
4 of 5 configs were re-measured today; 500M is carried from the prior report (see the regime where it fails below for why I didn’t re-run it live). ~1.5 GB of the card was held by a desktop/stream session during measurement — a headless card has more headroom.
the real 120M run
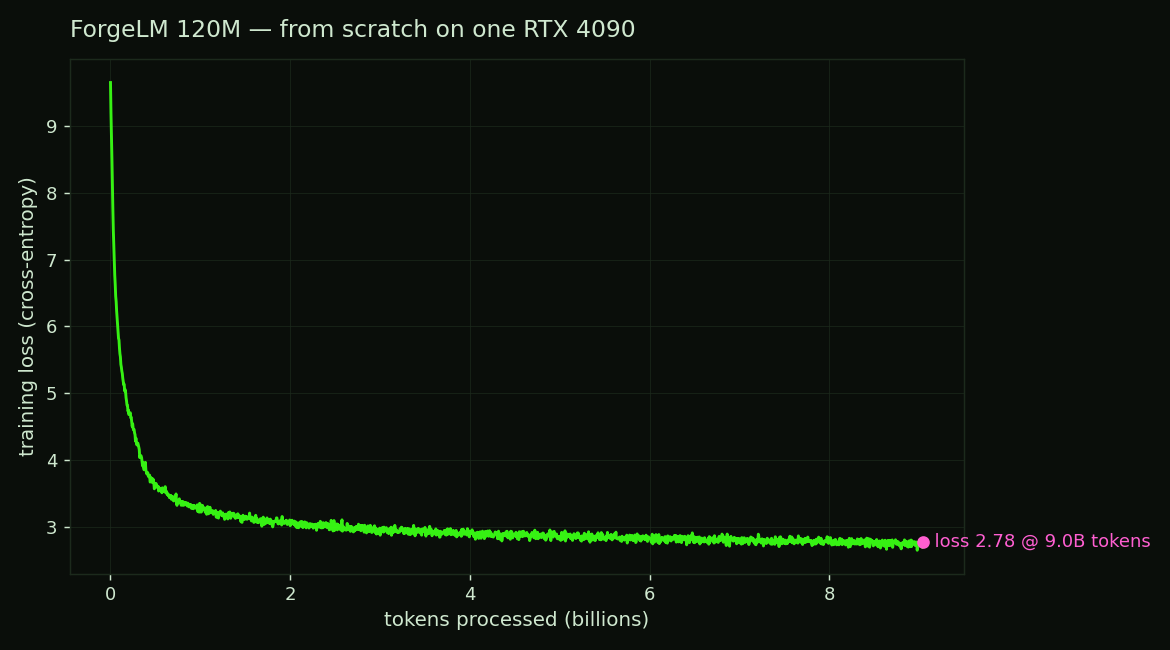
Loss 9.65 → 2.78 over 9.04 B tokens (17,250 steps). It sustained 126,078 tok/s (median; p10–p90 spanned 126,018–126,155 — almost flat) at a constant 11.6 GB. At that rate, 9 B tokens is ~20 hours of wall-clock on one card.
what this shows (and doesn’t)
The thing worth publishing: the real run beat the planner. The conservative forge plan
(compile off) said 120M would do 84.5k tok/s in 15.8 GB. The actual run did 126k tok/s in
11.6 GB with torch.compile on — ~1.5× faster and ~4 GB leaner. The practical envelope is
better than the spec sheet, which is the opposite of the usual hype direction.
A second honest quirk: VRAM is non-monotonic in parameters. 250M (13.2 GB) uses less than 120M (15.8 GB), because each config trades micro-batch for size — bigger models run smaller batches. Param count alone doesn’t predict whether a model fits.
What this does not show: any claim about model quality. No perplexity, no HellaSwag, no
ARC. Those need their own runs; the harness exists (forge eval) and the commands are in the
repo, but inventing the scores here would break the only rule that matters. Left as “run it.”
reproduce it
git clone https://github.com/Linutesto/forgelm && cd forgelm
# envelope (needs a CUDA GPU):
forge plan --config configs/120m.yaml
# or the whole proof drop (envelope + regenerate the loss curve):
cd benchmarks/single-4090-cost && ./run.shlimitations / the regime where it fails
- The 24 GB ceiling is real. 500M needs ~20.4 GB. With a desktop/stream session holding ~1.5 GB, it OOMs — which is exactly why I report 500M from the prior measurement instead of forcing a crash on the machine I’m typing this on. That’s the honest limit of the card, not a number to round away. Headless, or with a longer context, your mileage shifts.
- The planner is a floor, not a guarantee — real throughput depends on
torch.compilewarmup, data pipeline, and what else is on the GPU. - Throughput here is steady-state; it excludes one-time compile/warmup cost.
Yan Desbiens — work conducted at Éthiqueia Québec inc.